
A lot of messages
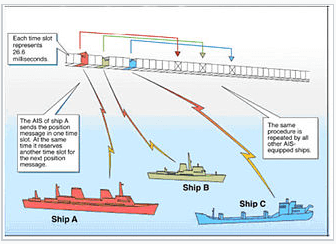 Most ships and larger boats carry a VHF collision avoidance system called Automatic Identification System (AIS). They broadcast messages containing information about their identity, current position, course and speed. Although VHF is a line of sight system, data from ships in mid-ocean is collected by satellite. There is a healthy business collecting the data, sanitising, storing and making it available for analysis. For example insurance brokers need to know when a ship arrives at its’ destination port so they can adjust their exposure.
Most ships and larger boats carry a VHF collision avoidance system called Automatic Identification System (AIS). They broadcast messages containing information about their identity, current position, course and speed. Although VHF is a line of sight system, data from ships in mid-ocean is collected by satellite. There is a healthy business collecting the data, sanitising, storing and making it available for analysis. For example insurance brokers need to know when a ship arrives at its’ destination port so they can adjust their exposure.
Dependent on speed, a ship can broadcast messages every few seconds. With several hundred thousand ships afloat, many thousands of messages per second are generated. This translates into peta-bytes a year of data that need stored.
The problem(s)
A FTSE 100 company had an existing business collecting, analysing and selling the data. They were struggling to cope with increased data volumes, particularly:
- Unreliability in communication between receiving stations and datacenter was causing message loss.
- To cope with data volumes they were having to aggregate messages, throwing away vital information.
- The relational database was struggling to cope with the increasing data volumes and unable to support new requirements for geo-spatial queries.
- The capabilities of the existing user interface was being surpassed by competitors.
- They were unable to exploit the market place for AIS class B message data – broadcast by more numerous smaller vessels.
How we helped
In the proof of concept phase we analysed the existing system (Java and relational database based) identifying the fundamental technical problems. We reverse engineered the business rules from the existing code, documenting them using Given-When-Then syntax. With the rules and scope agreed it was time to build the POC including:
- A new message receiving sub-system with web services and a persistent messaging layer (using RabbitMQ) to help solve the receiving system unreliability.
- A schema for the ElasticSearch database
- Created a server process that pulls batches of messages from the queue and efficiently inserts them into the database. For speed NodeJs and JavaScript were used.
- Developed geo-spatial queries to run against the ElasticSearch database. The results were displayed using a Google Maps component running in a web front-end implemented in React.
In the development phase we built out the front-end:
- Built features using a component based architecture for the front end based around React.
- Designed and implemented a testing strategy based around CucumberJS for acceptance tests and Jasmine for developer unit tests.
- Full developer and delivery environment for the front-end (using web-pack) to maximise productivity with features like hot-reload.
- Finally we created the deployment pipelines for a continuous delivery environment. Ansible, Packer and Terraform were used to provision and deploy the Amazon machine images (AMI’s)